We will talk about Linux Graphics stack components needed for using GPU functionality

X.Org Server:

Glamor :
X.Org Server:
------------------
X.Org Server refers to the free and open source implementation of the X Window System stewarded by the X.Org Foundation that includes not only the display server but also the client libraries (like Xlib and XCB), developer and user tools, and the rest of the components required to run an entire
X Window System architecture.
X org sever devided into 2 components:
Device Independent X (DIX) : The Device Independent X (DIX) is the part of the 2D graphics device driver, which is not specific to any hardware.
Device Dependent X (DDX) : The Device Dependent X (DDX) is the part of the 2D graphics device driver, which is hardware specific.
AMD's proprietary Catalyst includes such an extra device driver, just for the X.Org Server, additionally to the actual kernel blobs and user space device driver.
Glamor :
-----------
Glamor is a generic 2D acceleration driver for the X server that works translating the X render primitives to OpenGL operations, taking advantage of any existing 3D OpenGL drivers, proprietary and open-source.
The ultimate goal of GLAMOR is to obsolete and replace all the DDX, the device dependent X drivers, and acceleration architectures for them like XAA, EXA, UXA or SNA) by a single hardware independent 2D driver, avoiding the need to write X 2D specific drivers for every supported graphic
chipset. Glamor requires a 3D driver with shader support.
Glamor is a GL-based rendering acceleration library for X server:
------------------------------------------------------------------------------
- OpenGL based 2d rendering acceleration library. Transform x-rendering into OpenGL and EGL.
- It uses GL functions and shader to complete the 2D graphics operations.
- It uses normal texture to represent a drawable pixmap if possible.
- It calls GL functions to render to the texture directly.
- It’s somehow hardware independently. And could be a building block of any X server’s DDX driver.
Lets discuss to have a brief idea about OpenMax (Open Media Acceleration ):
-------------------------------------------------------------------------------------------------
OpenMAX provides three layers of interfaces:
Application layer (AL),
Integration layer (IL) and
Development layer (DL).
OpenMAX AL:
-----------------
1)It is the interface between multimedia applications, such as a media player, and the platform media framework.
2)It allows companies that develop applications to easily migrate their applications to different platforms (customers) that support the OpenMAX AL application programming interface (API)
OpemMAX IL:
------------------
1)It is the interface between media framework,(such as StageFright or MediaCodec API on Android, DirectShow on Windows, FFmpeg or Libav on Linux, or GStreamer for cross-platform), and a set of multimedia components (such as an audio or video codecs)
2)It allows companies that build platforms (e.g. allowing an implementation of an MP3 player) to easily change components like MP3 decoders and Equalizer effects and buy components for their platform from different vendors
In the OpenMAX IL, components represent individual blocks of functionality. Components can be sources, sinks, codecs, filters, splitters, mixers, or any other data operator. Depending on the implementation, a component could possibly represent a piece of hardware, a software codec,
another processor, or a combination thereof.
The OpenMAX IL API allows the user to load, control, connect, and unload the individual components. This flexible core architecture allows the Integration Layer to easily implement almost any media use case and mesh with existing graph-based media frameworks. The key focus of the OpenMAX IL API is portability of media components.
Applications using the GStreamer API would take advantage of hardware acceleration on platforms that provide it, when OMX IL support is integrated.
Bellagio is an open source OpenMAX IL implementation for Linux maintained by STMicroelectronics.
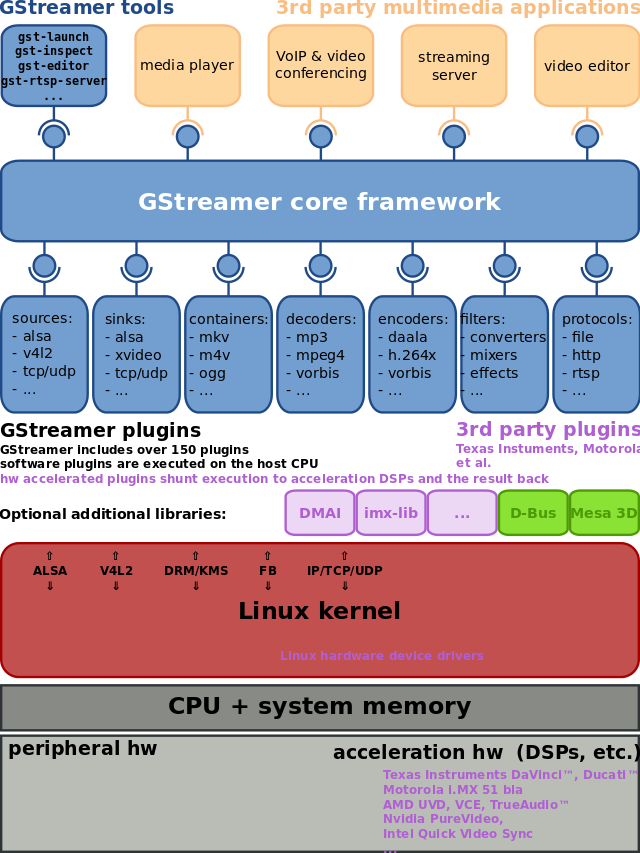
GStreamer (GST) is an open source multimedia framework used by several application, and it can use OpenMAX IL modules with its "gst-omx" module.

OpenMAX DL:
------------------
1)It is the interface between physical hardware, such as digital signal processor (DSP) chips and CPUs, and software, like video codecs and 3D engines.
2)It allows companies to easily integrate new hardware that supports OpenMAX DL without reoptimizing their low level software.
MESA (COMPUTER GRAPHICS) :
-----------------------------------------------
Mesa is a collection of free and open-source libraries that implement several rendering as well as video acceleration APIs related to hardware-accelerated 3D rendering, 3D computer graphics and GPGPU, the most prominent being OpenGL.

Hardware acceleration allows to use specific devices (usually graphical card or other specific devices) to perform multimedia processing. This allows to use dedicated hardware to perform demanding computation while freeing the CPU from such computations.
- VDPAU (Video Decode and Presentation API for Unix)
- Video Acceleration API (VA API)
- Direct-X Video Acceleration API
- Video Decoding API
VDPAU(Video Decode and Presentation API):
---------------------------------------------------------
Video Decode and Presentation API for Unix is an open source library and API to offload portions of the video decoding process and video post-processing to the GPU video-hardware.
1)Hardware decoding of MPEG-1, MPEG-2, MPEG-4 part 2, H.264, VC-1, and DivX 4 and 5 bitstreams on supported hardware, with a bitstream (VLD) level API.
2)Video post-processing including advanced deinterlacing algorithms, inverse telecine, noise reduction, configurable color space conversion, and procamp adjustments.
3)Sub-picture, on-screen display, and UI element compositing.
4) Direct rendering timestamp-based presentation of final video frames, with detailed frame delivery reports.
UVD is AMD's dedicated video decoding ASIC.
Video Codec Engine (VCE) is the name given to AMD's video encoding ASIC.
The free radeon driver supports Unified Video Decoder (UVD )and Video Codec Engine (VCE) through VDPAU and OpenMAX.
VDPAU (Video Decode and Presentation API for Unix), a competing API designed by NVIDIA, can potentially also be used as a backend for the VA API. If this is supported, any software that supports VA API then also indirectly supports a subset of VDPAU.
Video Acceleration API (VA API):
--------------------------------------------
The VA API specification was originally designed by Intel.
The main motivation for VA API is to enable hardware-accelerated video decode at various entry-points (VLD, IDCT, motion compensation, deblocking) for the prevailing coding standards today (MPEG-2, MPEG-4 ASP/H.263, MPEG-4 AVC/H.264, and VC-1/WMV3).
use case : vlc media player -> vaapi (Video Acceleration API) -> vdpau driver -> GPU ( Unified Video Decoder provided by AMD GPU)


Free and open-source graphics device driver:
------------------------------------------------------
- Most free and open source graphics device drivers are developed via the Mesa project.
- Linux kernel component DRM
- Linux kernel component KMS driver: basically the device driver for the display controller
- user-space component libDRM: a wrapper library for the system calls of the DRM, should only be used by Mesa 3D
- user-space component in Mesa 3D: this component is highly hardware specific, is being executed on the CPU and does the translation of e.g. OpenGL commands into machine code for the GPU; because of the split nature of the device driver, marshalling is possible;
- Mesa 3D is the only available free and open-source implementation of OpenGL, OpenGL ES, OpenVG, GLX, EGL and OpenCL as of July 2014 most of these components are written conforming to the Gallium3D-specifications;
DRI (Direct Rendering Infrastructure):
-------------------------------------------------
-The Direct Rendering Infrastructure (DRI) is a framework for allowing direct access to graphics hardware under the X Window System in a safe, efficient way.
-The main use of DRI is to provide hardware acceleration for the Mesa implementation of OpenGL.
-DRI implementation is scattered through the X Server and its associated client libraries, Mesa 3D and the Direct Rendering Manager kernel subsystem.

DRI is split into three parts:
-----------------------------------
1)the Direct Rendering Manager (DRM), a kernel component, for command checking and queuing (not scheduling).
2)the Mesa 3D device drivers, a userspace component, that does the translation of OpenGL commands into hardware specific commands; it prepares buffers of commands to be sent to the hardware by the DRM and interacts with the windowing system for synchronization of access to
the hardware
3)The hardware specific library libdrm implements the userspace interface to the kernel DRM. Libdrm contains a full set of functions to obtain information about encoders, connectors
use case : Application -> xlib -> xserver X.org -> mesa DRI driver -> libdrm -> drm -> GPU

Gallium3D:
--------------
DRI driver converts OpenGL->hardware translator. But Gallium3d driver interface will assume the presence of programmable vertex/fragment shaders and flexible memory objects.
1) Make drivers smaller and simpler.
Current DRI drivers are rather complicated. They're large, contain duplicated code and are burdened with implementing many concepts tightly tied to the OpenGL 1.x/2.x API.
2) Model modern graphics hardware.
The new driver architecture is an abstraction of modern graphics hardware, rather than an
OpenGL->hardware translator. The new driver interface will assume the presence of programmable vertex/fragment shaders and flexible memory objects.
3) Support multiple graphics APIs.
The reduced OpenGL 3.1+ APIs will be much smaller than OpenGL 1.x/2.x. We'd like a driver model that is API-neutral so that it's not tied to a specific graphics API.
4) Support multiple operating systems.
Gallium drivers have no OS-specific code (OS-specific code goes into the "winsys/screen" modules) so they're portable to Linux, Windows and other operating systems.


Direct Rendering Manager:
--------------------------------
The Direct Rendering Manager (DRM) is a subsystem of the Linux kernel responsible for interfacing with GPUs of modern video cards.
DRM exposes an API that user space programs can use to send commands and data to the GPU, and perform operations such as configuring the mode setting of the display.
Each GPU detected by DRM is referred as a DRM device, and a device file /dev/dri/cardX (where X is a sequential number) is created to interface with it.
A library called libdrm was created to facilitate the interface of user space programs with the DRM subsystem. This library is merely a wrapper that provides a function written in C for every ioctl of the DRM API

FFMPEG/libav:
-------------------
-libav is a library that contains all kinds of codecs, support for various container formats, some filters
-It's a library providing some API to use these things separately.
-Container parser, Software Implementation of Audio/Video decoders, SW Scaling
-Plain GStreamer can't do anything without plugins, GStreamer requires various plugins like, source(file,http,ftp,..), demux(mp4,3gp,flv,TS,..) & decoder(H.264,H.263,MP3,AAC). GStreamer is a broader library, and can actually use FFmpeg plugins.
Does FFMPEG use hardware acceleration?
FFmpeg provides a subsystem for hardware acceleration either uisng VDPAU , VAAPI , Direct X or other required API.
Lets discuss to have a brief idea about OpenMax (Open Media Acceleration ):
-------------------------------------------------------------------------------------------------
OpenMAX provides three layers of interfaces:
Application layer (AL),
Integration layer (IL) and
Development layer (DL).
OpenMAX AL:
-----------------
1)It is the interface between multimedia applications, such as a media player, and the platform media framework.
2)It allows companies that develop applications to easily migrate their applications to different platforms (customers) that support the OpenMAX AL application programming interface (API)
OpemMAX IL:
------------------
1)It is the interface between media framework,(such as StageFright or MediaCodec API on Android, DirectShow on Windows, FFmpeg or Libav on Linux, or GStreamer for cross-platform), and a set of multimedia components (such as an audio or video codecs)
2)It allows companies that build platforms (e.g. allowing an implementation of an MP3 player) to easily change components like MP3 decoders and Equalizer effects and buy components for their platform from different vendors
In the OpenMAX IL, components represent individual blocks of functionality. Components can be sources, sinks, codecs, filters, splitters, mixers, or any other data operator. Depending on the implementation, a component could possibly represent a piece of hardware, a software codec,
another processor, or a combination thereof.
The OpenMAX IL API allows the user to load, control, connect, and unload the individual components. This flexible core architecture allows the Integration Layer to easily implement almost any media use case and mesh with existing graph-based media frameworks. The key focus of the OpenMAX IL API is portability of media components.
Applications using the GStreamer API would take advantage of hardware acceleration on platforms that provide it, when OMX IL support is integrated.
Bellagio is an open source OpenMAX IL implementation for Linux maintained by STMicroelectronics.
GStreamer (GST) is an open source multimedia framework used by several application, and it can use OpenMAX IL modules with its "gst-omx" module.
OpenMAX DL:
------------------
1)It is the interface between physical hardware, such as digital signal processor (DSP) chips and CPUs, and software, like video codecs and 3D engines.
2)It allows companies to easily integrate new hardware that supports OpenMAX DL without reoptimizing their low level software.
MESA (COMPUTER GRAPHICS) :
-----------------------------------------------
Mesa is a collection of free and open-source libraries that implement several rendering as well as video acceleration APIs related to hardware-accelerated 3D rendering, 3D computer graphics and GPGPU, the most prominent being OpenGL.
Hardware acceleration allows to use specific devices (usually graphical card or other specific devices) to perform multimedia processing. This allows to use dedicated hardware to perform demanding computation while freeing the CPU from such computations.
- VDPAU (Video Decode and Presentation API for Unix)
- Video Acceleration API (VA API)
- Direct-X Video Acceleration API
- Video Decoding API
VDPAU(Video Decode and Presentation API):
---------------------------------------------------------
Video Decode and Presentation API for Unix is an open source library and API to offload portions of the video decoding process and video post-processing to the GPU video-hardware.
1)Hardware decoding of MPEG-1, MPEG-2, MPEG-4 part 2, H.264, VC-1, and DivX 4 and 5 bitstreams on supported hardware, with a bitstream (VLD) level API.
2)Video post-processing including advanced deinterlacing algorithms, inverse telecine, noise reduction, configurable color space conversion, and procamp adjustments.
3)Sub-picture, on-screen display, and UI element compositing.
4) Direct rendering timestamp-based presentation of final video frames, with detailed frame delivery reports.
UVD is AMD's dedicated video decoding ASIC.
Video Codec Engine (VCE) is the name given to AMD's video encoding ASIC.
The free radeon driver supports Unified Video Decoder (UVD )and Video Codec Engine (VCE) through VDPAU and OpenMAX.
VDPAU (Video Decode and Presentation API for Unix), a competing API designed by NVIDIA, can potentially also be used as a backend for the VA API. If this is supported, any software that supports VA API then also indirectly supports a subset of VDPAU.
Video Acceleration API (VA API):
--------------------------------------------
The VA API specification was originally designed by Intel.
The main motivation for VA API is to enable hardware-accelerated video decode at various entry-points (VLD, IDCT, motion compensation, deblocking) for the prevailing coding standards today (MPEG-2, MPEG-4 ASP/H.263, MPEG-4 AVC/H.264, and VC-1/WMV3).
use case : vlc media player -> vaapi (Video Acceleration API) -> vdpau driver -> GPU ( Unified Video Decoder provided by AMD GPU)

Free and open-source graphics device driver:
------------------------------------------------------
- Most free and open source graphics device drivers are developed via the Mesa project.
- Linux kernel component DRM
- Linux kernel component KMS driver: basically the device driver for the display controller
- user-space component libDRM: a wrapper library for the system calls of the DRM, should only be used by Mesa 3D
- user-space component in Mesa 3D: this component is highly hardware specific, is being executed on the CPU and does the translation of e.g. OpenGL commands into machine code for the GPU; because of the split nature of the device driver, marshalling is possible;
- Mesa 3D is the only available free and open-source implementation of OpenGL, OpenGL ES, OpenVG, GLX, EGL and OpenCL as of July 2014 most of these components are written conforming to the Gallium3D-specifications;
DRI (Direct Rendering Infrastructure):
-------------------------------------------------
-The Direct Rendering Infrastructure (DRI) is a framework for allowing direct access to graphics hardware under the X Window System in a safe, efficient way.
-The main use of DRI is to provide hardware acceleration for the Mesa implementation of OpenGL.
-DRI implementation is scattered through the X Server and its associated client libraries, Mesa 3D and the Direct Rendering Manager kernel subsystem.
DRI is split into three parts:
-----------------------------------
1)the Direct Rendering Manager (DRM), a kernel component, for command checking and queuing (not scheduling).
2)the Mesa 3D device drivers, a userspace component, that does the translation of OpenGL commands into hardware specific commands; it prepares buffers of commands to be sent to the hardware by the DRM and interacts with the windowing system for synchronization of access to
the hardware
3)The hardware specific library libdrm implements the userspace interface to the kernel DRM. Libdrm contains a full set of functions to obtain information about encoders, connectors
use case : Application -> xlib -> xserver X.org -> mesa DRI driver -> libdrm -> drm -> GPU
Gallium3D:
--------------
DRI driver converts OpenGL->hardware translator. But Gallium3d driver interface will assume the presence of programmable vertex/fragment shaders and flexible memory objects.
1) Make drivers smaller and simpler.
Current DRI drivers are rather complicated. They're large, contain duplicated code and are burdened with implementing many concepts tightly tied to the OpenGL 1.x/2.x API.
2) Model modern graphics hardware.
The new driver architecture is an abstraction of modern graphics hardware, rather than an
OpenGL->hardware translator. The new driver interface will assume the presence of programmable vertex/fragment shaders and flexible memory objects.
3) Support multiple graphics APIs.
The reduced OpenGL 3.1+ APIs will be much smaller than OpenGL 1.x/2.x. We'd like a driver model that is API-neutral so that it's not tied to a specific graphics API.
4) Support multiple operating systems.
Gallium drivers have no OS-specific code (OS-specific code goes into the "winsys/screen" modules) so they're portable to Linux, Windows and other operating systems.
Direct Rendering Manager:
--------------------------------
The Direct Rendering Manager (DRM) is a subsystem of the Linux kernel responsible for interfacing with GPUs of modern video cards.
DRM exposes an API that user space programs can use to send commands and data to the GPU, and perform operations such as configuring the mode setting of the display.
Each GPU detected by DRM is referred as a DRM device, and a device file /dev/dri/cardX (where X is a sequential number) is created to interface with it.
A library called libdrm was created to facilitate the interface of user space programs with the DRM subsystem. This library is merely a wrapper that provides a function written in C for every ioctl of the DRM API
FFMPEG/libav:
-------------------
-libav is a library that contains all kinds of codecs, support for various container formats, some filters
-It's a library providing some API to use these things separately.
-Container parser, Software Implementation of Audio/Video decoders, SW Scaling
-Plain GStreamer can't do anything without plugins, GStreamer requires various plugins like, source(file,http,ftp,..), demux(mp4,3gp,flv,TS,..) & decoder(H.264,H.263,MP3,AAC). GStreamer is a broader library, and can actually use FFmpeg plugins.
Does FFMPEG use hardware acceleration?
FFmpeg provides a subsystem for hardware acceleration either uisng VDPAU , VAAPI , Direct X or other required API.


